在小菜初学scrapy时,从google上发现了几篇非常不错的文章,未经博主同意擅自将博主的文章收藏,主要怕日后看时,找不到此文章。小菜在这里向博主致敬,希望看到这篇帖子的小伙伴能够阅读原贴。
在爬虫领域,使用最多的主流语言主要是Java和Python这两种,而开源爬虫框架Scrapy正是由Python编写的。
Scrapy在开源爬虫框架中名声很大,几乎用Python写爬虫的人,都用过这个框架。市场上很多爬虫框架都是模仿和参考Scrapy的思想和架构实现的,如果想深入学习爬虫,研读Scrapy的源码还是很有必要的。
这个系列的文章主要记录自己当时做爬虫时,读源码的思路和经验整理,本篇先从宏观角度介绍整个Scrapy的架构和运行流程。
1.介绍
Scrapy是一个基于Python编写的一个开源爬虫框架,它可以帮你快速、简单的方式构建爬虫,并从网站上提取你所需要的数据。
也就是说,使用Scrapy能帮你快速简单的编写一个爬虫,用来抓取网站数据
这里不再介绍Scrapy的安装和使用,本系列主要通过阅读源码讲解Scrapy实现思路为主。如果有不懂如何使用的同学,请参考官方网站或官方文档学习。(写本篇文章时,Scrapy版本为1.2)
因为使用比较简单,使用Scrapy官网上的例子来说明如何构建爬虫:
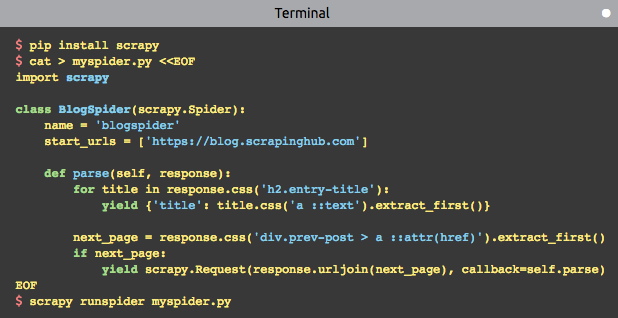
简单来说构建和运行一个爬虫只需完成以下几步:
- 使用
scrapy startproject创建爬虫模板或自己编写爬虫脚本 - 爬虫类继承
scrapy.Spider,重写parse方法 parse方法中yield或return字典、Request、Item- 使用
scrapy crawl <spider_name>或scrapy runspider <spider_file.py>运行
经过简单的几行代码,就能采集到某个网站下一些页面的数据,非常方便。但是在这背后到底发生了什么?Scrapy到底是如何帮助我们工作的呢?
2.架构
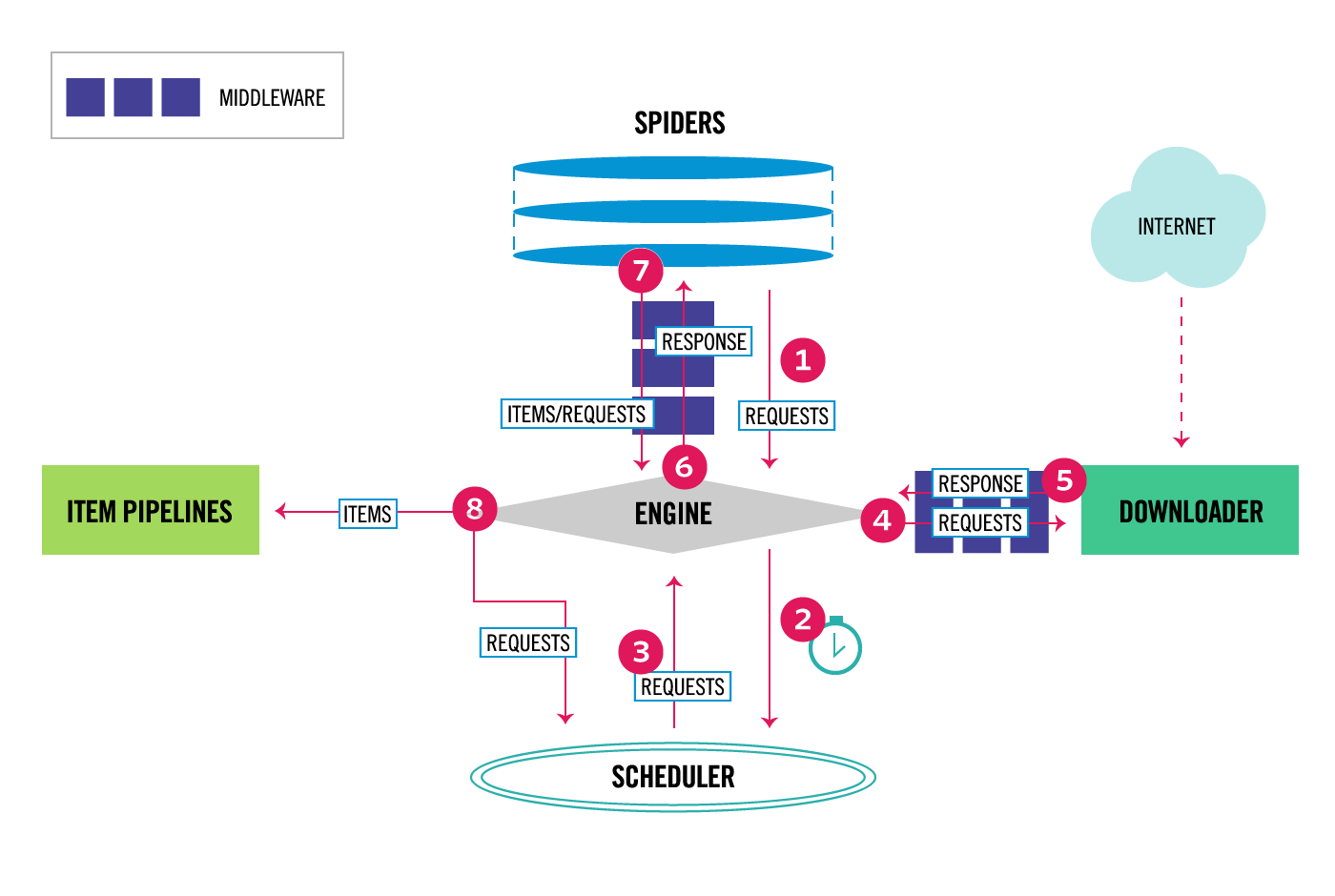
3.核心组件
Scrapy有以下几大组件:
Scrapy Engine:核心引擎,负责控制和调度各个组件,保证数据流转Scheduler:负责管理任务、过滤任务、输出任务的调度器,存储、去重任务都在此控制Downloader:下载器,负责在网络上下载网页数据,输入待下载URL,输出下载结果Spiders:用户自己编写的爬虫脚本,可自定义抓取意图Item Pipeline:负责输出结构化数据,可自定义输出位置Downloader middlewares:介于引擎和下载器之间,可以在网页在下载前、后进行逻辑处理Spider middlewares:介于引擎和爬虫之间,可以在调用爬虫输入下载结果和输出请求/数据时进行逻辑处理
4.数据流转
按照架构图的序号,数据流转大概是这样的:
引擎从自定义爬虫中获取初始化请求(也叫种子URL)- 擎把该请求放入
调度器中,同时引擎向调度器获取一个待下载的请求(这两部是异步执行的) - 调度器返回给引擎一个
待下载的请求 - 引擎发送请求给
下载器,中间会经过一系列下载器中间件 - 这个请求通过下载器下载完成后,生成一个
响应对象,返回给引擎,这中间会再次经过一系列下载器中间件 - 引擎接收到下载返回的响应对象后,然后发送给爬虫,执行
自定义爬虫逻辑,中间会经过一系列爬虫中间件 - 爬虫执行对应的回调方法,处理这个响应,完成用户逻辑后,会生成
结果对象或新的请求对象给引擎,再次经过一系列爬虫中间件 - 引擎把爬虫返回的结果对象交由
结果处理器处理,把新的请求对象通过引擎再交给调度器 - 从1开始重复执行,直到调度器中没有新的请求处理
5.核心组件交互图
我在读完源码后,整理出一个更详细的架构图,其中展示了更多相关组件的细节:
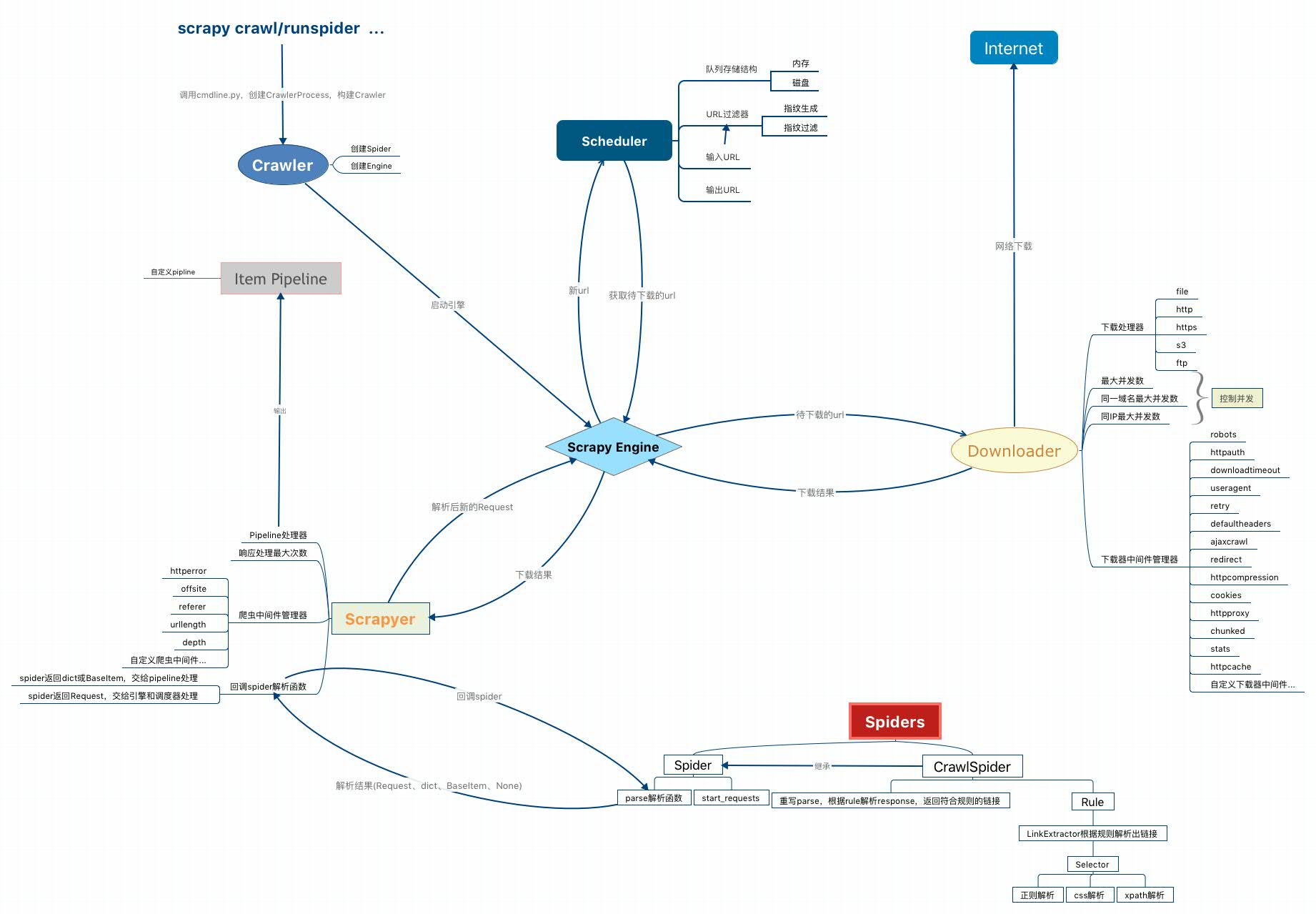
这里需要说明一下图中的Scrapyer,其实这也是在源码的一个核心类,但官方架构图中没有展示出来,这个类其实是处于Engine、Spiders、Pipeline之间,是连通这3个组件的桥梁,后面在文章中会具体讲解。
6.核心类图
涉及到的一些核心类如下:
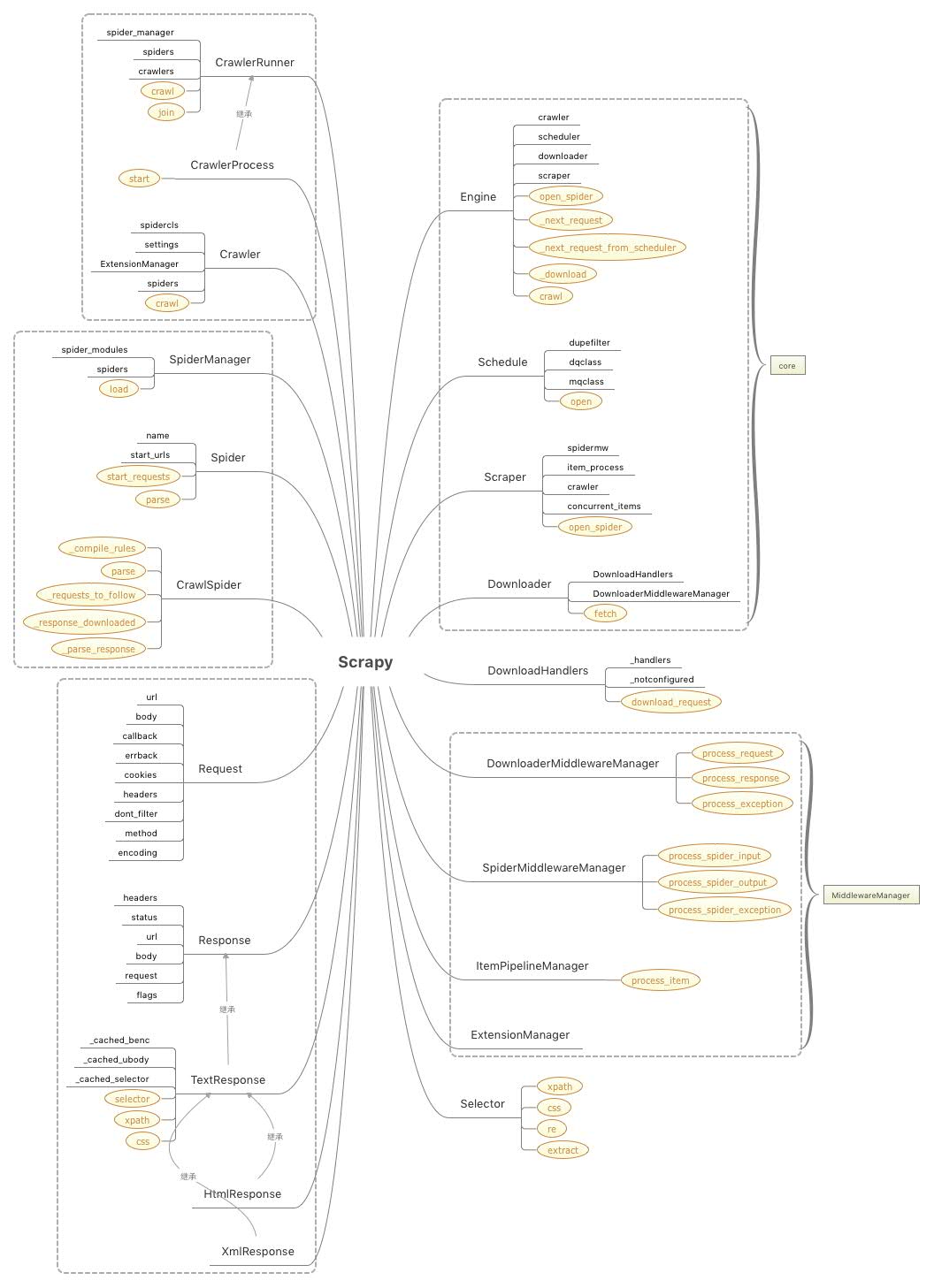
其中标没有样式的黑色文字是类的核心属性,黄色样式的文字都是核心方法。
可以看到,Scrapy的核心类,其实主要包含5大组件、4大中间件管理器、爬虫类和爬虫管理器、请求、响应对象和数据解析类这几大块。
大家先对整个架构有个认识,接下来的文章,会针对上述的这些类和方法进行源码讲解。