上小节从无到有写了一个完整的小爬虫,本小节我们继续练习爬虫。相信小伙伴已经知道我们这次爬取的目标是谁了,爬取知乎比爬取下厨房困难一些,原因就是知乎的反爬机制比下厨房的反爬机制更完善。知乎查看问答,必须要登录。我们要想爬取知乎的数据,首先得让程序自动登录。
1.session和cookie自动登录机制
cookie
HTTP Cookie(也叫Web Cookie或浏览器Cookie)是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。通常,它用于告知服务端两个请求是否来自同一浏览器,如保持用户的登录状态。Cookie使基于无状态的HTTP协议记录稳定的状态信息成为了可能。
cookie自动登录
由于HTTP是一种无状态协议,通俗点就是没有记录客户端的状态信息。当A浏览器向服务器发送一个请求,服务返回数据。然后B浏览器向服务器发送请求,服务器返回数据。但是服务器无法识别出A浏览和B浏览器到底哪个是A,哪个是B。服务器要想识别出A和B,在数据返回时,将A和B的状态信息也一起返回去,下次A浏览器请求时,就会携带A的状态信息,服务器通过状态信息就能够识别谁是A,谁是B。
用户敏感信息直接存放在cookie中是不安全的,当用户请求被拦截时,通过请求所携cookie带信息就能分析出用户的敏感信息。
session
session 是一个抽象概念,开发者为了实现中断和继续等操作,将 user agent 和 server 之间一对一的交互,抽象为“会话”,进而衍生出“会话状态”,也就是 session 的概念。一次会话过程,这个过程是连续的,也可以时断时续的。session是存放在服务器内存,这个不同于cookie。
session自动登录
首先浏览器请求服务器访问web站点时,程序需要为客户端的请求创建一个session的时候,服务器首先会检查这个客户端请求是否已经包含了一个session标识、称为SESSIONID,如果已经包含了一个sessionid则说明以前已经为此客户端创建过session,服务器就按照sessionid把这个session检索出来使用,如果客户端请求不包含session id,则服务器为此客户端创建一个session并且生成一个与此session相关联的session id,sessionid 的值应该是一个既不会重复,又不容易被找到规律以仿造的字符串,这个sessionid将在本次响应中返回到客户端保存,保存这个sessionid的方式就可以是cookie,这样在交互的过程中,浏览器可以自动的按照规则把这个标识发回给服务器,服务器根据这个sessionid就可以找得到对应的session。
2.创建scrapy项目
创建一个scrapy爬取知乎问答的项目,具体的创建方式请小伙伴参考上一小节,具体这里就不在演示了。
创建好后的项目结构:
zhihu
|-zhihu
|--spiders
|--__init__.py
|--zh.py
|--__init__.py
|--items.py
|--middlewares.py
|--pipelines.py
|--settings.py
|-scrapy.cfg
3.创建爬虫启动文件
为了方便调试,我们写一个爬虫的启动文件main.py,存放位置
zhihu
|-zhihu
|--spiders
|--__init__.py
|--zh.py
|--__init__.py
|--items.py
|--middlewares.py
|--pipelines.py
|--settings.py
|-scrapy.cfg
+|-mian.py
编写mian.py文件
import os
import sys
from scrapy.cmdline import execute
curr_path = os.path.abspath(__file__)
dir_path = os.path.dirname(curr_path)
if __name__ == "__main__":
sys.path.append(dir_path)
execute(["python -m scrapy","crawl","zh"])
注意:python虚拟环境要设置正确
4.安装selenium
知乎的自动登录我们要借助selenium插件完成,后面我们会继续介绍selenium的。
anaconda 中安装selenium
#安装selenium
conda install selenium
#检查
pip list
5.下载安装ChromeDriver
下载ChromeDriver,下载前,需要查看自己chrome浏览器的版本。帮助 -> 关于google chrome
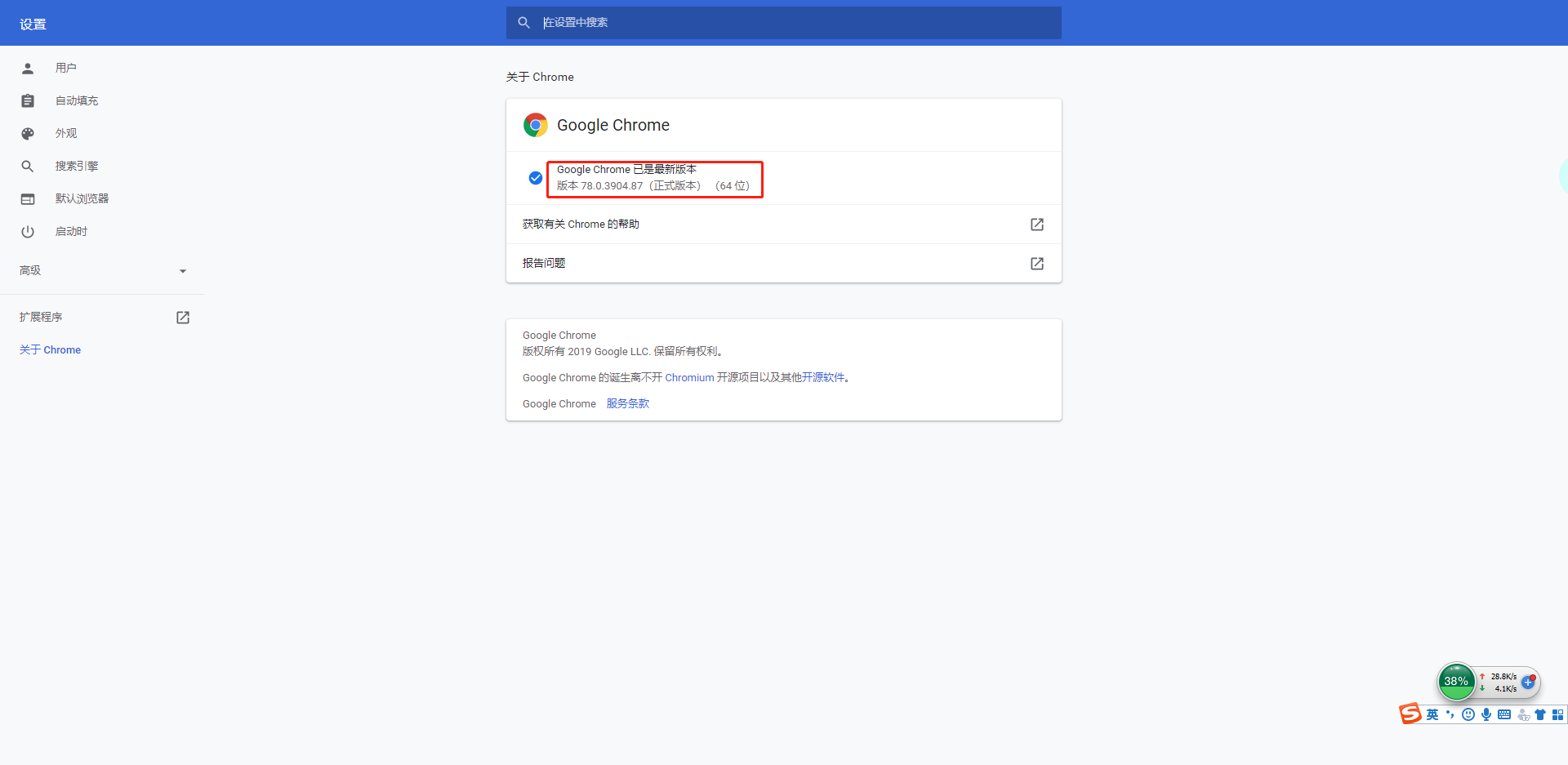
小菜这里的chrome版本是78,所以要找到支持chrome浏览器78版本ChromeDriver。然后根据自己的操作系统选择对应的版本
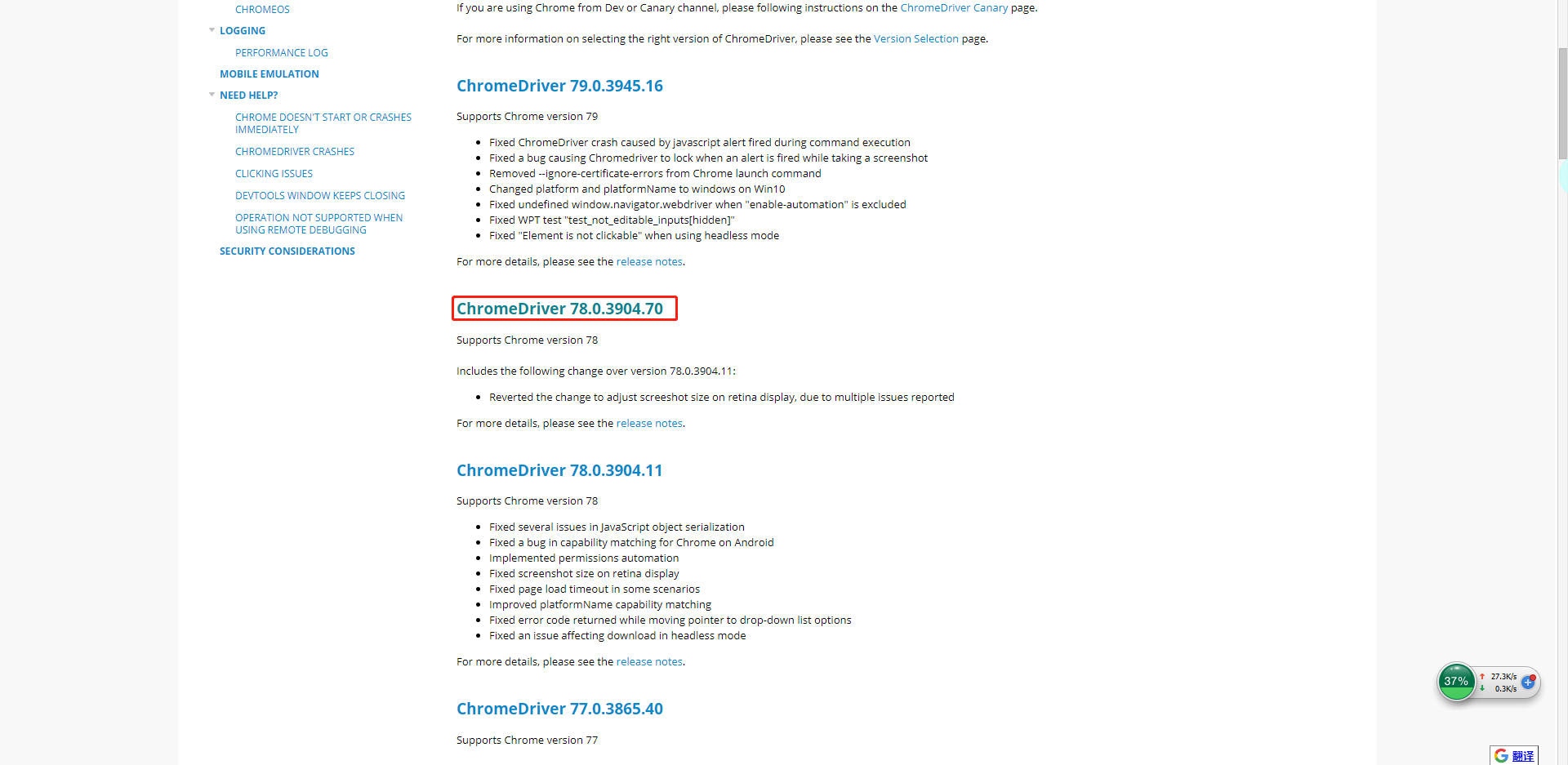

小菜用的是windows系统,所以下载的是win32。下载完后,解压。要记住解压后的路径,后面我们有用到,小菜的路径是E:\chromedriver_win32\chromedriver.exe
6.模拟登陆
安装好selenium和ChromeDriver,下面就来模拟知乎登陆。先展示下生成的zh.py代码
spider/zh.py
import scrapy
class ZhSpider(scrapy.Spider):
name = 'zh'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com/hot']
def parse(self, response):
pass
在爬取知乎前,首先我们要在爬虫入口登陆知乎。在spider类中,爬虫的入口是start_requests(),所以我们只需要重载start_requests()方法就可以了。
配置settings.py
在settings.py最下面添加,路径就是刚才解压的chromdriver,大家要填写自己的路径。
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
#Obey robots.txt rules
ROBOTSTXT_OBEY = False
# 配置ChromeDriver启动路径
CHROMEDRIVER_PATH = 'E:/chromedriver_win32/chromedriver.exe'
# 配置知乎账号
USER_NAME = '1**********3'
USER_PASSWD = '**********'
zh.py中 添加 start_requests()方法
import scrapy
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
class ZhSpider(scrapy.Spider):
name = 'zh'
allowed_domains = ['zhihu.com']
start_urls = ['https://www.zhihu.com/hot']
def start_requests(self):
option = webdriver.ChromeOptions()
#这里去掉window.navigator.webdriver的特性
option.add_experimental_option('excludeSwitches', ['enable-automation'])
chromeDirver = self.settings["CHROMEDRIVER_PATH"]
browser = webdriver.Chrome(executable_path=chromeDirver, options=option)
browser.get("https://www.zhihu.com/signin")
browser.find_elements_by_css_selector(".SignFlow .SignFlow-tab")[1].click()
time.sleep(2)
browser.find_element_by_css_selector(".SignFlow-account input[name='username']").send_keys(Keys.CONTROL + 'a')
browser.find_element_by_css_selector(".SignFlow-account input[name='username']").send_keys(self.settings["USER_NAME"])
time.sleep(2)
browser.find_element_by_css_selector(".SignFlow-password input[name='password']").send_keys(Keys.CONTROL + 'a')
browser.find_element_by_css_selector(".SignFlow-password input[name='password']").send_keys(self.settings["USER_PASSWD"])
time.sleep(2)
browser.find_element_by_css_selector(".SignFlow .Button.SignFlow-submitButton").click()
def parse(self, response):
pass
重启main.py文件,可以看到selenium调用chromedirver来成功模拟登陆知乎。可能也会有小伙伴登陆不成功,登陆不成功大概会是这么两种情况:
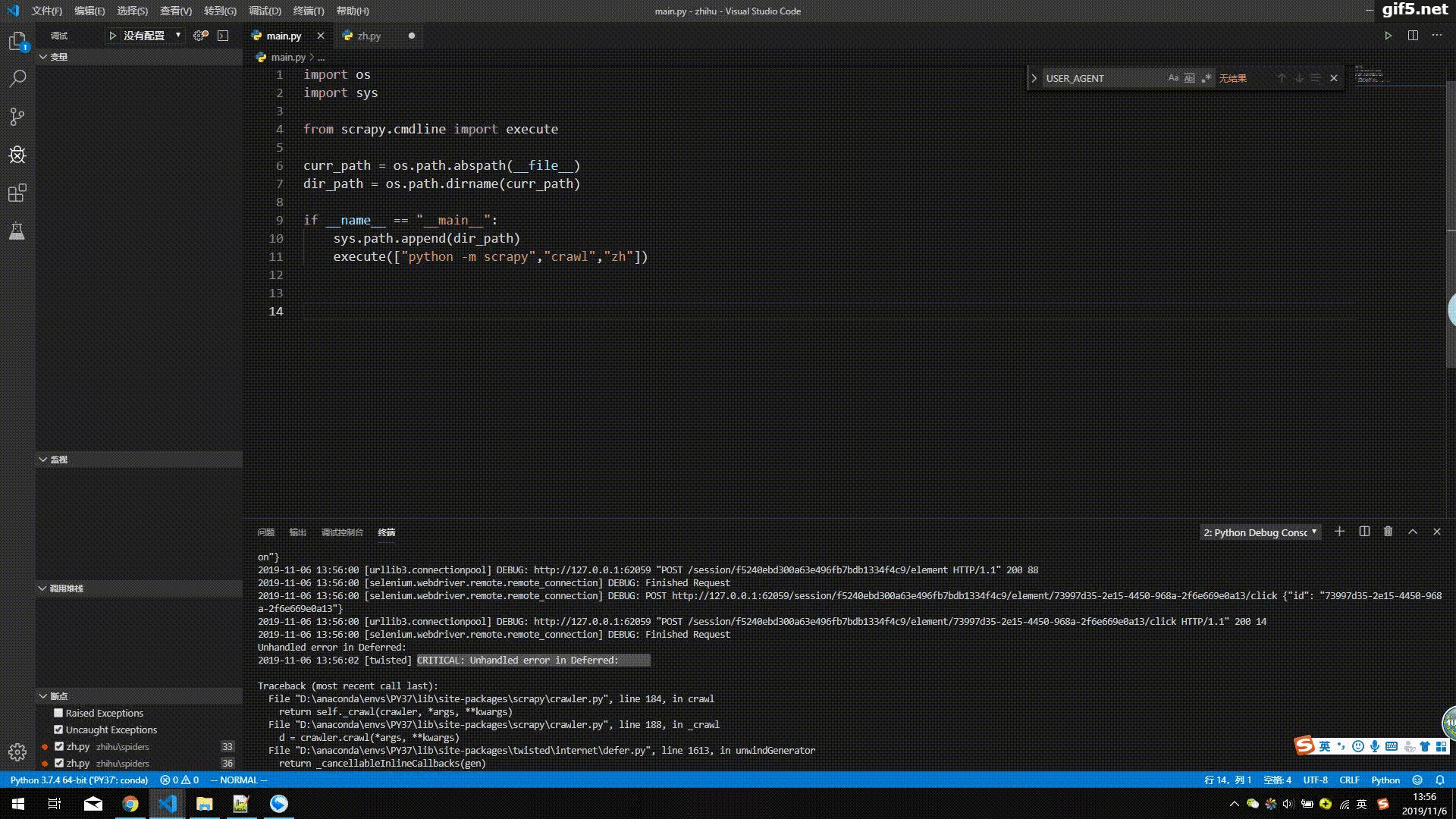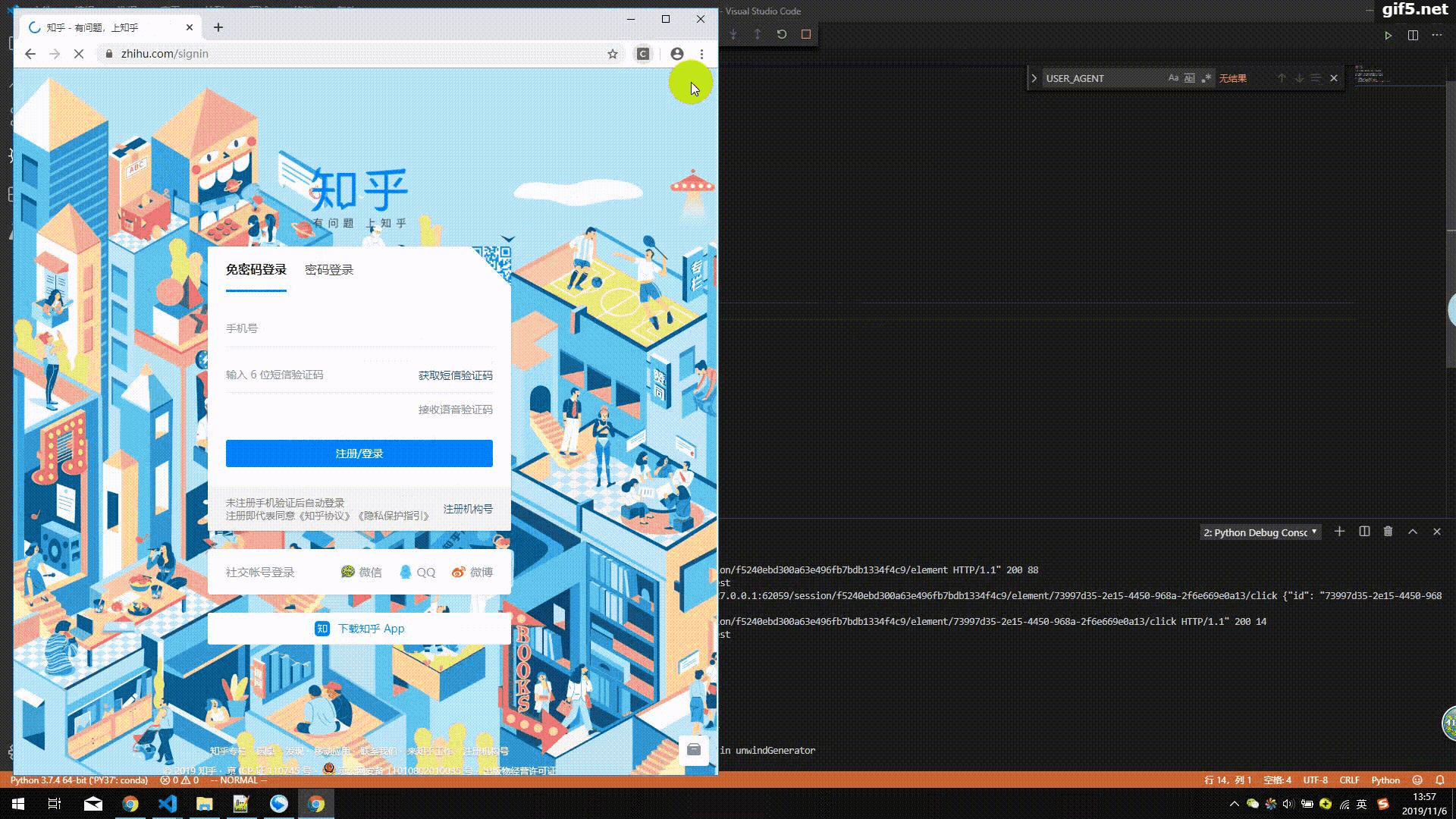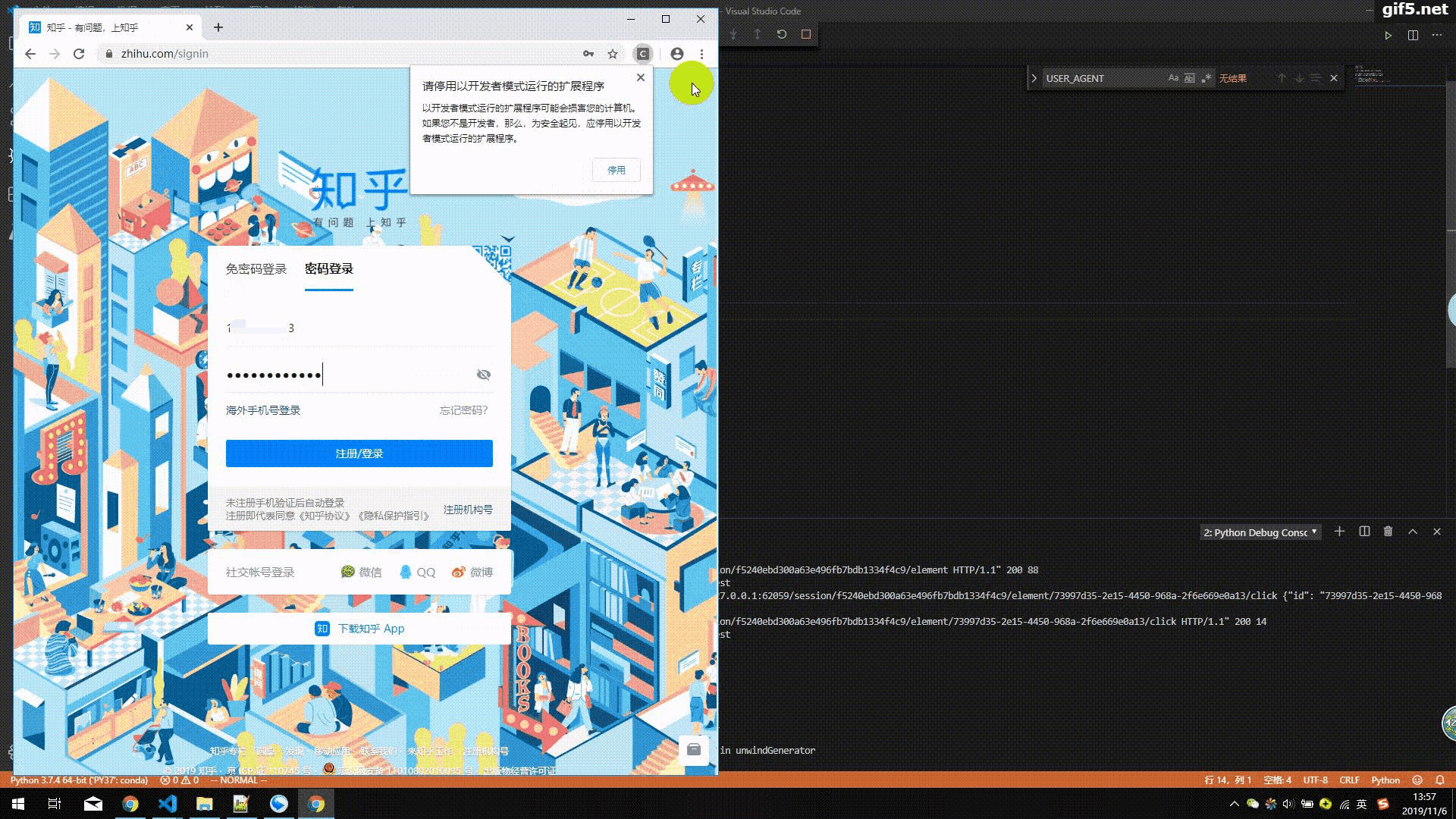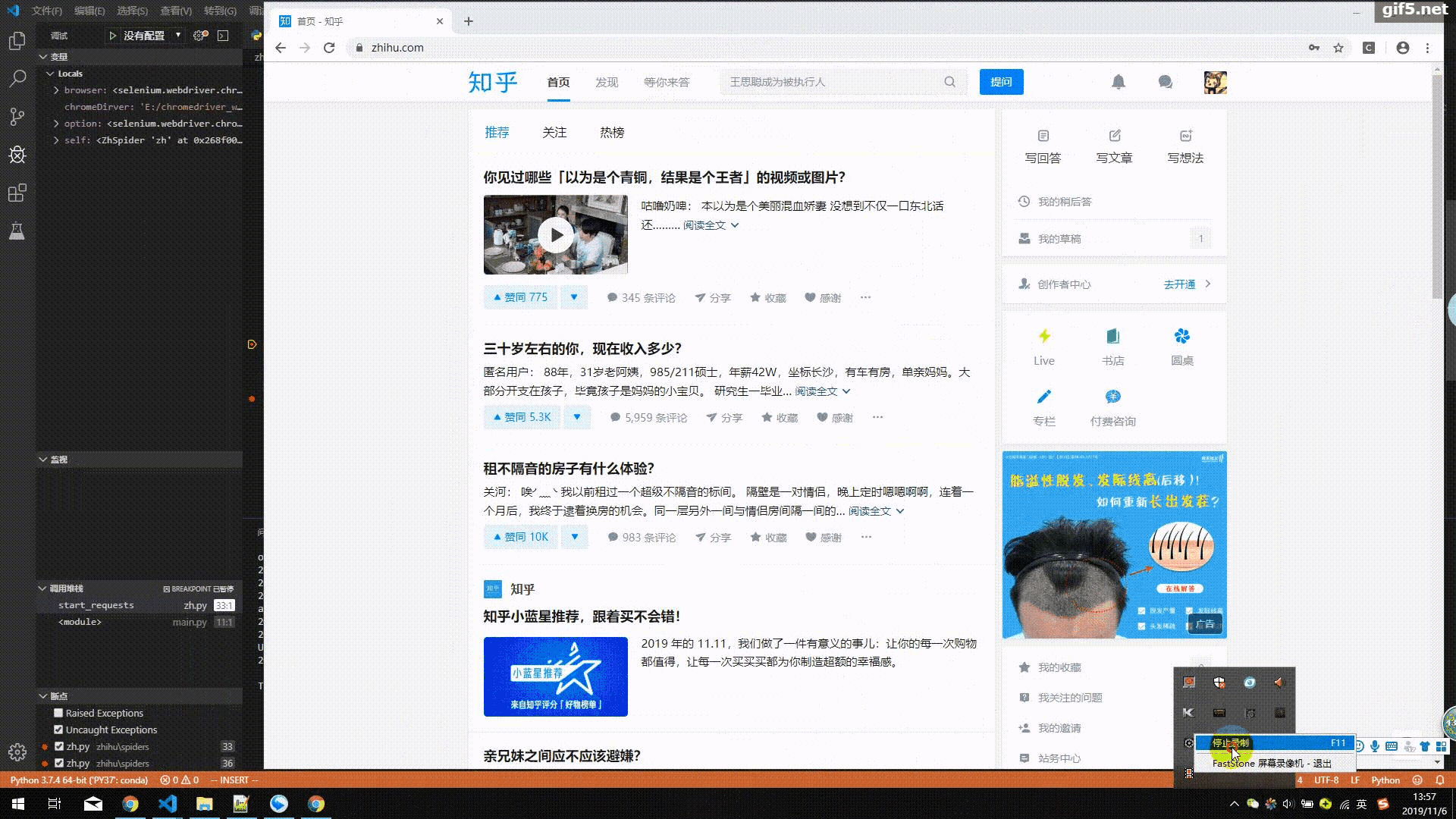
7.系统性实现知乎验证
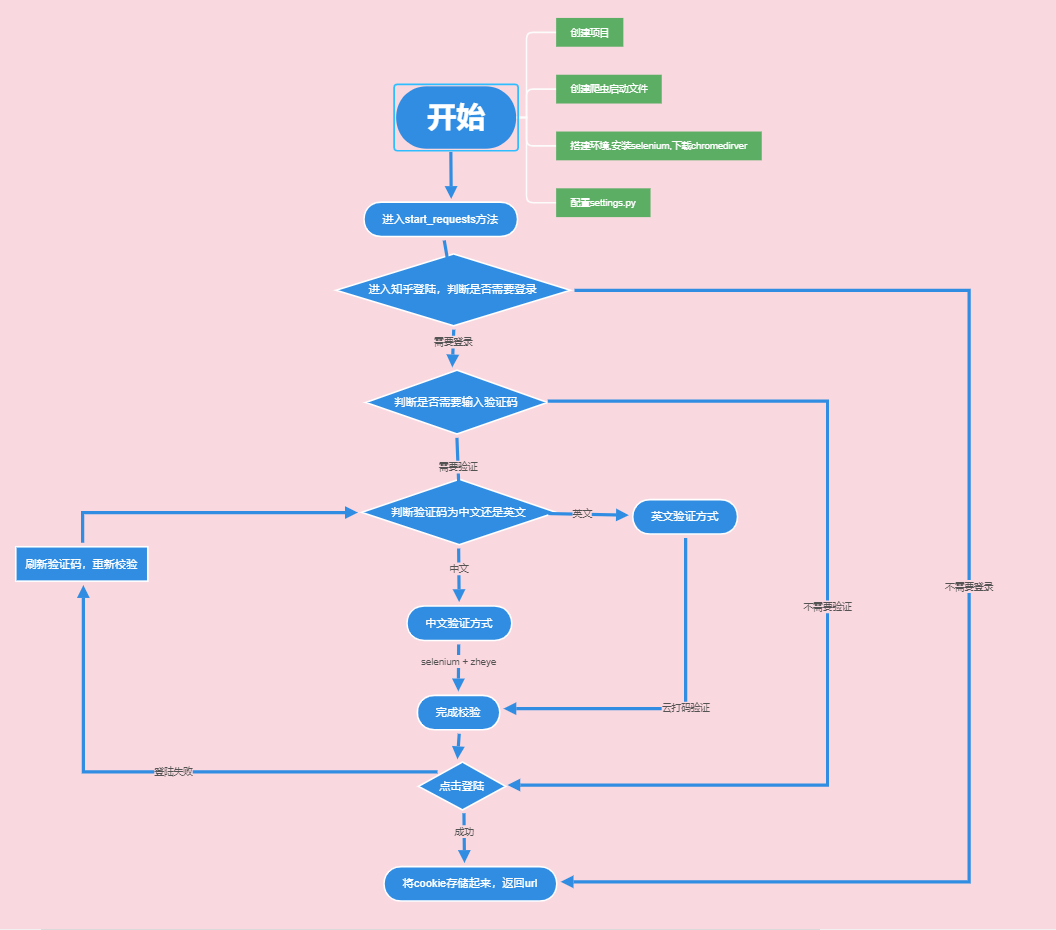
上面只是简单验用selenium来模拟一个登陆。真实情况稍微复杂点,下面放一张模拟知乎登陆流程图。后面就整体实现下
####