在初学scrapy时,按照官方的文档写了一个爬虫片段,发现怎么都会不会进入parse()方法。下面是spider代码
import scrapy
class XcfSpider(scrapy.Spider):
name = 'xcf'
allowed_domains = ['xiachufang.com']
start_urls = ['https://www.xiachufang.com/category/731/']
def parse(self, response):
pass
1.403问题
在parse()方法内部打一个断点,重新运行爬虫。
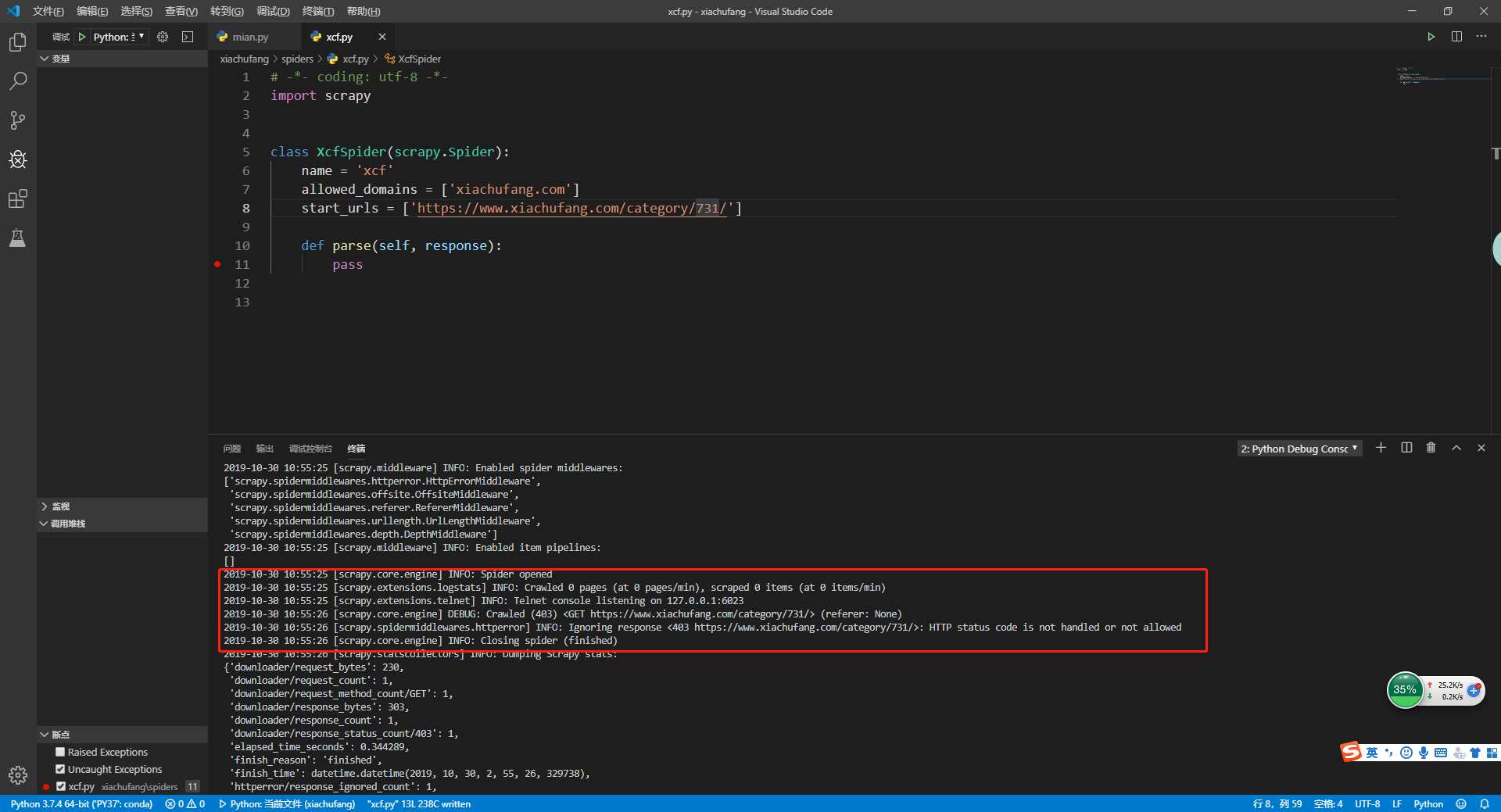
看到输出信息中有一个403的状态码,正常的请求中response状态码是200。在生成项目时,有一个设置项目settings.py文件。能够找到这段代码
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'xiachufang (+http://www.yourdomain.com)
在默认情况下,用户代理USER_AGENT被设置成这样。
解决方案
打开settings.py文件,将USER_AGENG修改为
USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'
然后重启项目
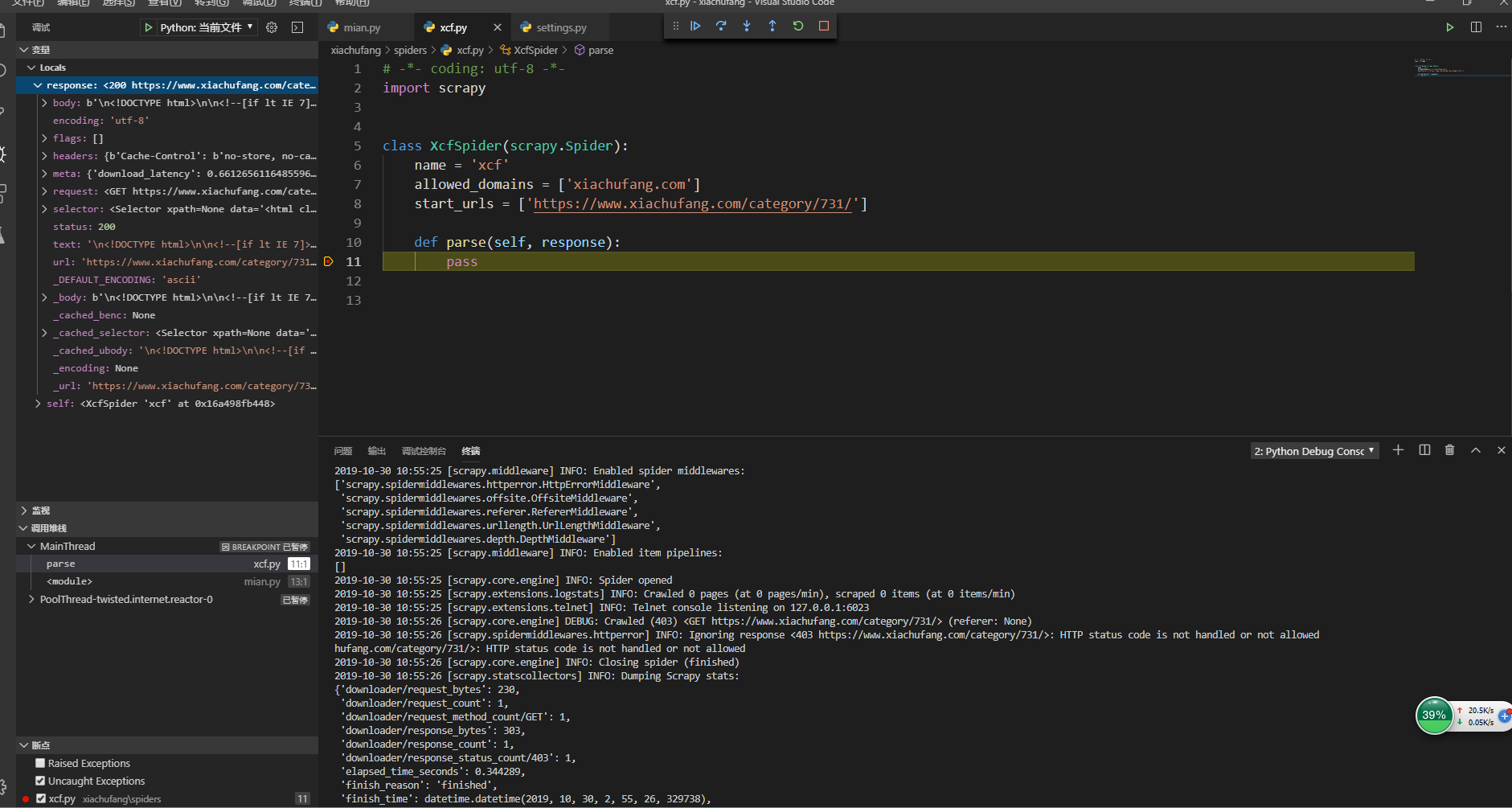
发现进入parse()方法,代码在断点处停下来
2.总结
对于有些网站,可能会检查USER_AGENt,恰好小菜就碰到了。将上面的url修改https://baidu.com就可以进入断点。推测百度可能没有做限制。
总结:
- 在调试时,要多看控制台的信息输出
- spider只有在
response响应状态为200时才会进入parse()方法