在计算机科学中,查找表(Lookup Table)是用简单的查询操作替换运行时计算的数组或者关联数组这样的数据结构。由于从内存中提取数值经常要比复杂的计算速度快很多,所以这样得到的速度提升是很显著的。
| 关键字 | 描述 | 示例 |
|---|
| AS | (别名)修改显示字段 | select hello as ‘名字’ |
| DISTINCT | 去重复关键字,SELECT DISTINCT 语句用于返回唯一不同的值 | select distinct c_type from commodity; |
| WHERE | 条件 | SELECT column_name,column_name
FROM table_name
WHERE column_name operator value; |
| BETWEEN AND | 取值范围 | select c_name,c_inprice
from commodity
where c_inprice between 10 and 100; |
| NOT BETWEEN AND | 不在这个取值范围 | select c_name,c_inprice
from commodity
where c_inprice not between 10 and 100; |
| IS NULL | 选项有null值 | select c_name ,c_inprice,c_outprice
from commodity
where c_outprice is null; |
| IS NOT NULL | 选项没有null值 | select c_name ,c_inprice,c_outprice
from commodity
where c_outprice is not null; |
| IN | (10,20,30,40) 括号条件满足任意一个,是or关系 | select c_name,c_inprice,c_outprice
from commodity
where c_inprice in (20,10,30,40); |
| NOT IN | (10,20,30,40) 不满足以上全部条件 | select c_name,c_inprice,c_outprice
from commodity
where c_inprice not in (20,10,30,40); |
| LIKE | 和通配符搭配
‘_‘任意一个字符
’%’ 匹配任意多个字符,包括零个字符
没有通配符修饰 效果等同于’=’
’%%’表示全部 | select c_name
from commodity
where c_name like ‘%以%’; |
| ORDER BY | 排序(默认升序) | select c_name,c_inprice
from commodity
order by c_inprice; |
| ORDER BY 字段 desc | 降序 | select c_name,c_inprice
from commodity
order by c_inprice desc; |
| LIMIT | limit 值1,值2
值1表示下标,值2表示多少行; 当只有一个值时,那就表示前多少行 | select c_name,c_outprice
from commodity
where c_outprice is not null
order by c_outprice desc
limit 5; |
| GROUP BY | 分组 | select count(*),c_type
from commodity
group by c_type; |
| HAVING | 可以和统计函数一起使用,如果查询语句中出现两个关键字where和having,则where优先级大于having;
是where将限制语句输出之后,having根据输出结果来进行判断
HAVING子句必须位于GROUP BY之后ORDER BY之前 | |
1.常用系统函数
| 函数名 | 描述 |
|---|
| count() | 统计记录个数,参数是字段,也可以是count(*) |
| avg() | 统计平均值,参数是字段,但是数据类型是整型 |
| max() | 最大值 |
| min() | 最小值 |
2.常用语句
查询语句 select
select * from table_name;
删除语句 delete
delete from table_name
where c_name='中国';
更新数据 update
update table_name
set column1=value1,column2=value2
where some_colum=some_value;
清空表数据 truncate
有外键约束的不能删除
truncate table table_name
添加数据 inser into
inser into table_name
values (value1,value2,value3,...);
--或者
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
小菜在这里链接一个测试的表,想练习的小伙伴们下载练习表查询sql表
3.子查询
在一个表表达中可以调用另一个表表达式,这个被调用的表表达式叫做子查询(subquery)
使用子查询原则
- 一个子查询必须放在圆括号中
- 将子查询放在比较条件的右边以增加可读性。子查询不包含 ORDER BY 子句。对一个 SELECT 语句只能用一个 ORDER BY 子句,并且如果指定了它就必须放在主 SELECT 语句的最后
- 在子查询中可以使用两种比较条件:单行运算符(>, =, >=, <, <>, <=) 和多行运算符(IN, ANY, ALL)
按照对返回结果的调用方法:
- where型子查询:把内层查询结果当作外层查询的比较条件
- from型子查询:把内层的查询结果供外层再次查询
- exists型子查询:把外层查询结果拿到内层,看内层的查询是否成立
where型子查询
where型的子查询就是把内层查询的结果当作外层查询的条件
--查找'4'(net)课程成绩最高学生姓名
SELECT s.s_name
FROM student s
WHERE s.s_id = (
SELECT sc.s_id
FROM score sc
WHERE sc.c_id = 4
ORDER BY sc.s_score DESC
LIMIT 1
)
from型子查询
from子查询就是把子查询的结果(内存里的一张表)当作一张临时表,然后再对它进行处理
--查询'3'(java)课程比'4'(net)课程成绩高的所有学生的学号
SELECT a.s_id
FROM (SELECT * FROM score sc WHERE sc.c_id = 3) a,
(SELECT * FROM score sc WHERE sc.c_id = 4) b
WHERE a.s_id = b.s_id
AND a.s_score > b.s_score;
exists型子查询
exists子查询就是对外层表进行循环,再对内表进行内层查询。和in ()差不多,但是它们还是有区别的。主要是看两个张表大小差的程度。若子查询表大则用exists(内层索引),子查询表小则用in(外层索引)
--查询学生姓名和老师姓名冲突的人
SELECT s.s_name
FROM student s
WHERE EXISTS (
SELECT t.t_name
FROM teacher t
WHERE s.s_name = t.t_name
)
--也可以转换成in
SELECT s.s_name
FROM student s
WHERE s.s_name in (
SELECT t.t_name
FROM teacher t
)
在sql中需要使用两张表以上时,需要使用join,join又分为5种:
- 内连接(INNER)
- 全外连接(FULL OUTER)
- 左外连接(LEFT OUTER)
- 右外连接(RIGHT OUTER)
- 交叉连接(CROSS)
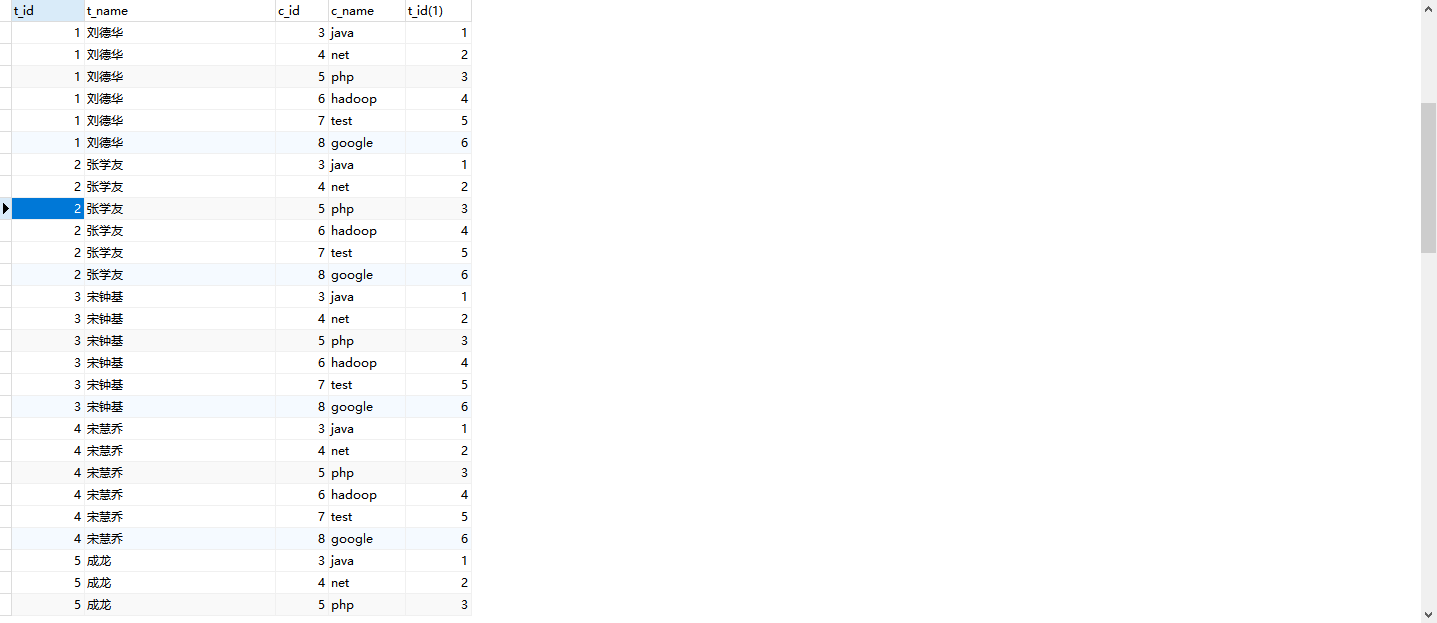
4.内连接
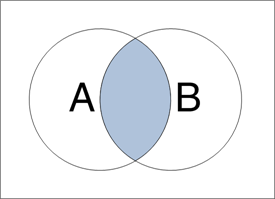
内连接Inner join 基于连接谓词将两张表(如A 和 B)的列组合在一起,产生新的结果集(其实就是两张表的公共部分,可以理解为两个圆的交集)。
SELECT *
FROM teacher t INNER JOIN course c on t.t_id = c.c_id;

5.全外连接
完整外部联接返回左表和右表中的所有行。当某行在另一个表中没有匹配行时,则另一个表的选择列表列包含空值。如果表之间有匹配行,则整个结果集行包含基表的数据值。使用全连接可以得到以下两种结果
注意:mysql中不支持full join操作,但是可以通过左连接并上右连接达到全连接效果
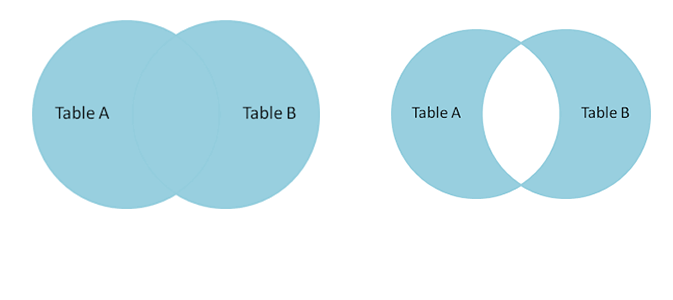
SELECT *
FROM teacher t
LEFT JOIN course c ON t.t_id = c.t_id
UNION ALL
SELECT *
FROM course c
RIGHT JOIN teacher t ON t.t_id = c.t_id
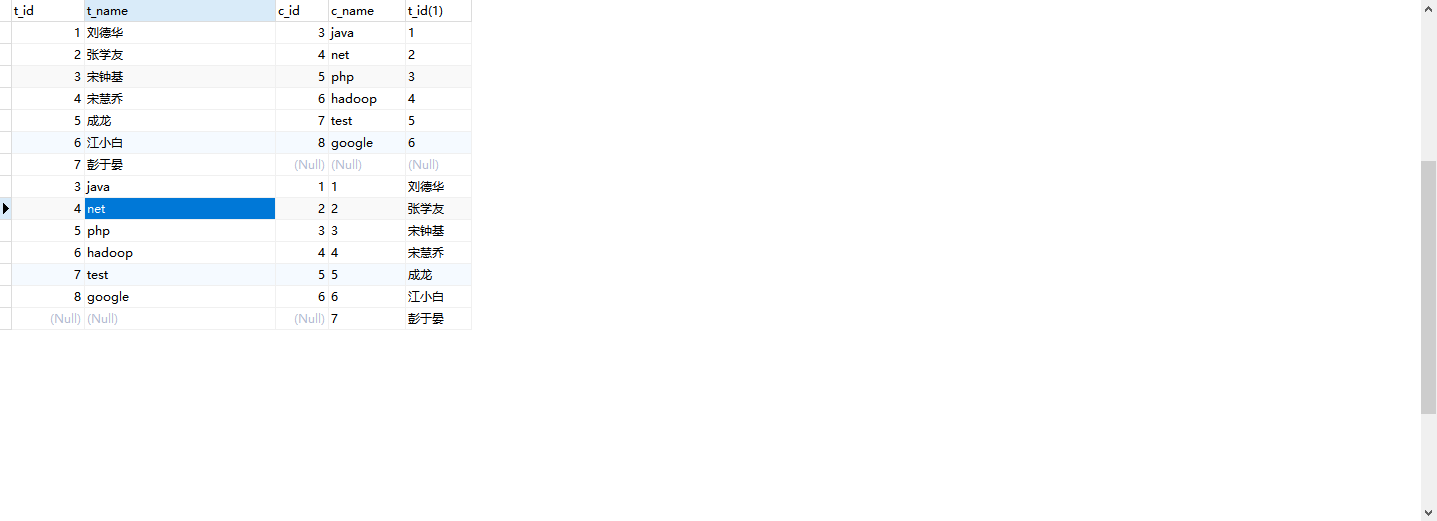
6.左外连接
LEFT JOIN关键字会将左表作为主表(A),将返回所有行,即使在右表(B)中没有匹配的行会以NULL显示。
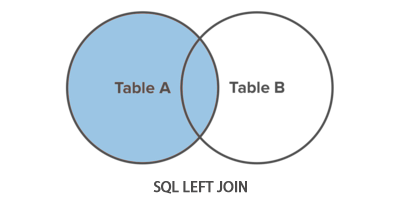
SELECT *
FROM teacher t LEFT JOIN course c on t.t_id = c.t_id

7.右外连接
RIGHT JOIN 关键字会右表作为主表(B),将返回所有行,即使在左表(A)中没有匹配的行会以NULL显示。
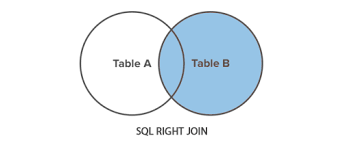
SELECT *
FROM teacher t RIGHT JOIN course c on t.t_id = c.t_id

8.交叉连接
交叉联接返回左表中的所有行,左表中的每一行与右表中的所有行组合。交叉联接也称作笛卡尔积
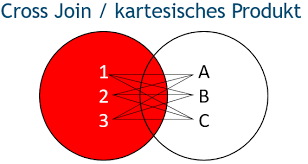
SELECT *
FROM teacher CROSS JOIN course